

引入java的HTML解析器jsoup。
jar引用
maven引用
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
以爬取我个人网站首页图片为例
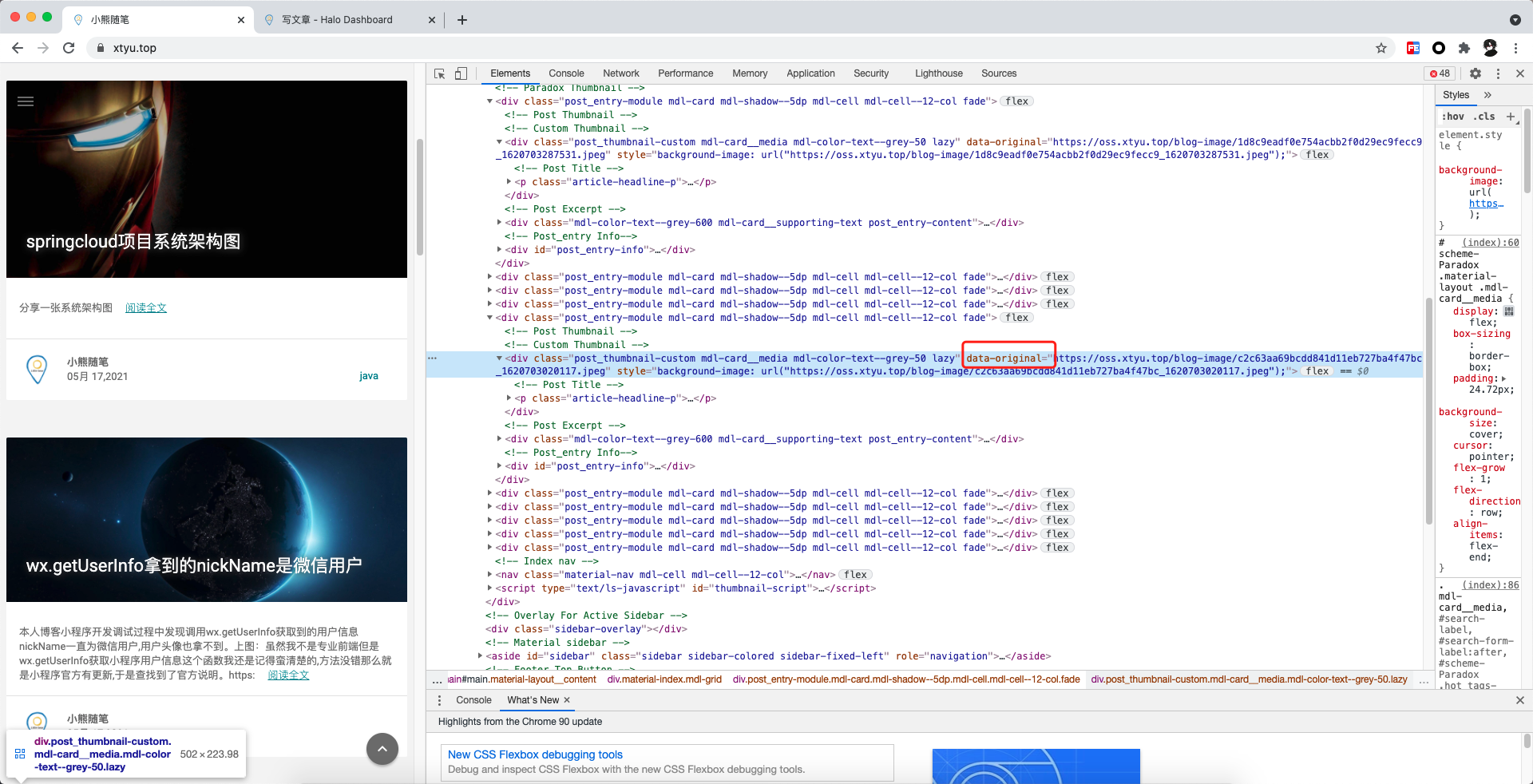
我们先打开浏览器调试模式查看需要爬取的图片,很明显图片地址放在div标签data-original属性内
java代码
public static void main(String[] args) {
String html = getHtmlFromUrl("https://www.xtyu.top/","utf-8");//下载html源码
Document doc = Jsoup.parse(html);
Elements elements = doc.select("div[data-original]");//找到对应的所有标签 ps:工具网页标签类型不同灵活配置
//遍历出所有data-original
for(Element e : elements){
String url =e.attr("data-original");
System.out.println(url);
//如果资源是相对路径则拼接一下url
if (url.indexOf("http")==-1){
url = url.replace("../","https://www.xtyu.top/");
}
//下载到指定目录
download(url,"/Users/smile/Desktop/测试爬取/");
}
}
//根据网址返回网页源代码
public static String getHtmlFromUrl(String url,String encoding){
StringBuffer html = new StringBuffer();
InputStreamReader isr=null;
BufferedReader buf=null;
String str = null;
try {
URL urlObj = new URL(url);
URLConnection con = urlObj.openConnection();
isr = new InputStreamReader(con.getInputStream(),encoding);
buf = new BufferedReader(isr);
while((str=buf.readLine()) != null){
html.append(str+"\n");
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(isr != null){
try {
buf.close();
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return html.toString();
}
//下载文件到指定目录
public static void download(String url,String path){
File file= null;
FileOutputStream fos=null;
String downloadName= url.substring(url.lastIndexOf("/")+1);
HttpURLConnection httpCon = null;
URLConnection con = null;
URL urlObj=null;
InputStream in =null;
byte[] size = new byte[1024];
int num=0;
try {
file = new File(path+downloadName);
fos = new FileOutputStream(file);
if(url.startsWith("http")){
urlObj = new URL(url);
con = urlObj.openConnection();
httpCon =(HttpURLConnection) con;
in = httpCon.getInputStream();
while((num=in.read(size)) != -1){
for(int i=0;i<num;i++)
fos.write(size[i]);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally{
try {
in.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
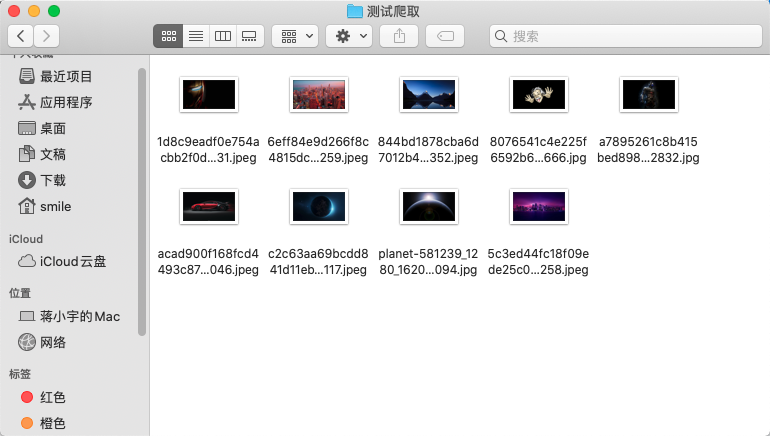
结果
评论区